Dec 22, 2022
5 Data Preparation Tips for Better Machine Learning Models

Jennifer Prendki
Founder and CEO, Alectio

If you’ve spent much time working on machine learning projects, you may have already learned data-centric AI’s dirty little secret: it’s mostly about cleaning and organizing the data.
Differentiated machine learning models don’t necessarily result from differentiating the model itself (anyone can use an open source model like BERT as their starting point, for example). Instead, they’re the product of differentiated data. Just as the right instructor can turn an average student into an all-star, the right data can drastically improve model performance.
What do we mean by “the right data?” High-quality data is clean, consistent, accurate, and presented in a format the model can understand. Here are five ways to ensure you’re training your model with nothing but the best.
1. Collect Enough Data in the First Place
How much data is enough to train a model? According to Google, “As a rough rule of thumb, your model should train on at least an order of magnitude more examples than trainable parameters. Simple models on large data sets generally beat fancy models on small data sets. Google has had great success training simple linear regression models on large data sets.”
In other words, it depends. To illustrate this, Google notes that a simple iris flower data set only needs 150 examples before the model can distinguish between three varieties of iris. By contrast, Google’s gmail SmartReply needs a training data set of 238 million examples before it can recognize and predict human language.
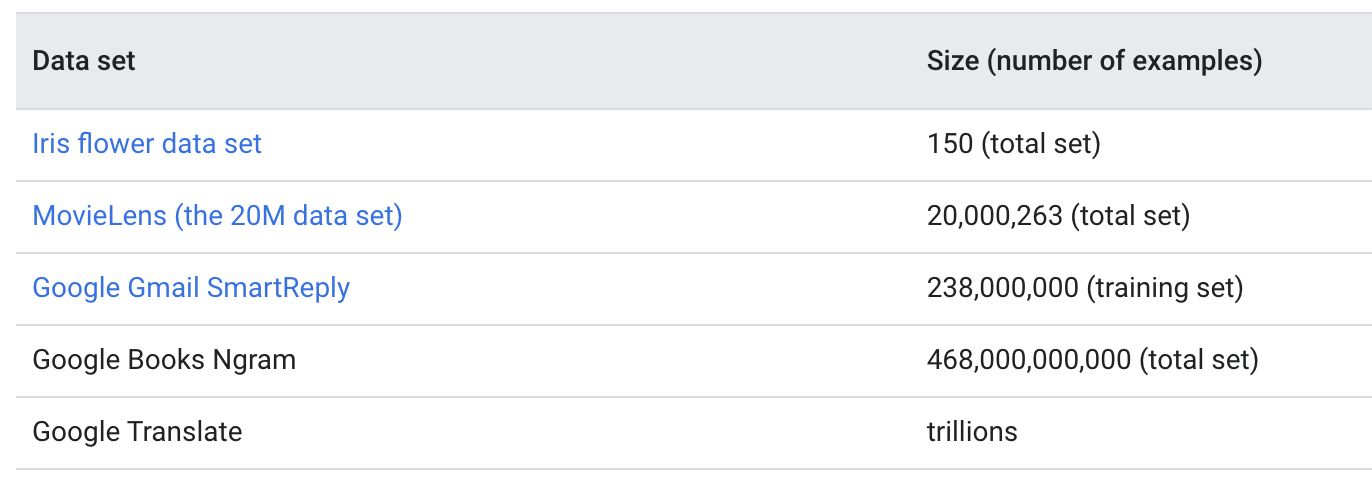
In all of these examples, the size of the data set correlates with the complexity of the desired results.
2. Handle Missing Values and Other Structural Errors
Missing values can be misinterpreted by machine learning models as different classes or features of the data set, leading to inaccurate results. And as rigorous as your data collection methods may be, these errors crop up all the time. For example, if a survey participant doesn't respond to a question on the form, that question will hit your data set as a missing value.
To tackle missing values, you have two main options:
1) Replace the missing observation with an estimated value, like an average (also known as imputation)
2) Exclude records without values (also known as “omission from analysis")
While you’re here, check for other structural errors. Are there corrupted values? Duplicate data? Incorrect or skewed information? Now is the time to address it.
3. Identify and Remove Outliers
Outliers are data points that don’t follow the general pattern of the data set. A classic example is the student who scores unusually high marks on an exam. Just as a single student can throw off the grading curve for the rest of the class, outliers can cause problems for machine learning models. They’re not necessarily wrong, but they can skew your results in a way that influences the accuracy of model predictions.
There are also times when outliers are caused by errors in the data collection process, such as mistakes in data entry or faulty sensors.
To identify and remove outliers from your data set, you might consider using statistical techniques such as the interquartile range (IQR) or the Z-score to identify the outliers in your data. Or you could visualize the data, leveraging charts and plots to notice patterns and spot outliers. Once you’ve identified an outlier, manually remove it or justify your reason for keeping it.
4. Format Your Data So It’s Consistent
Make sure your data is formatted correctly and there aren’t any errors or inconsistencies. Reformatting your data may include fixing typos, standardizing the file type you’re using (e.g., CSV, Excel), standardizing the structure of the data (e.g., number of columns and rows), and standardizing the data types (e.g., all numbers are integers and all text is strings). The goal is to serve the data in a consistent format the model can understand.
5. Reduce the Amount of Data You’re Using
We know, we started this list encouraging you to collect enough data. By this stage, though, start thinking, “Less is more.” Including too much data can actually be counterproductive; it’s often best to whittle down your data set until it closely fits the tasks you want the model to perform.
Here are a few common ways to trim the fat from your data set:
- Attribute sampling: Attribute sampling is when only include in your data set the attributes that are most important for predicting the target value. For example, if you want to predict which customers are likely to make large purchases in an online store, you might consider including their age, location, and gender as attributes, but you’d exclude their credit card numbers because it’s not relevant for the task at hand.
- Record sampling: Record sampling involves removing records with missing, erroneous, or less representative values to improve the accuracy of your predictions. You started this process when you addressed your missing values.
- Aggregation: Instead of including every individual data point, divide the data into groups and summarize it. Do you need to pull daily sales reports, or will summarizing the monthly data take you to the same place? Aggregation can help reduce the size of the data set and the computational time required to process it, without significantly impacting the accuracy of your predictions.
Interested in Learning More?
We have much more to show you! Join us for our course DataPrepOps and the Practice of Data-Centric AI, where you’ll learn about data-centric AI techniques like data labeling, data augmentation, active learning, and more.
In the field of data-centric AI, why do we pay such little formal attention to data preparation when it impacts our outcomes so enormously? That question led course instructor Jennifer Prendki to start Alectio, the first startup focused solely on automating and operationalizing DataPrepOps – and it’s the same question that drives her course. We’re thrilled that Jennifer will be sharing her know-how with a new cohort of Uplimit students, helping them appreciate both the practical and theoretical side of machine learning.
The four-week long course starts February 6, so grab your spot soon!