Jan 31, 2023
A Quick Guide to Orchestrating Data Pipelines with Apache Airflow

Henry Weller
Data Engineer at MongoDB

We’re thrilled to announce that we’ve partnered with the data engineering experts at Astronomer to launch our new course offering, Effective Data Orchestration with Airflow! Beginning February 6, this four-week long course will introduce you to Airflow 2.5, the latest release of the popular open source platform. We’ll walk you through everything you need to know about using Airflow to programmatically author, schedule, and monitor workflows to orchestrate reliable and cost-effective data pipelines.
If you’re interested in mastering an increasingly in-demand skill and growing more competitive in your machine learning or data science career, this is the course for you!
To celebrate our new course and provide a taste of what you’re in store for, we’ve written a quick-and-dirty guide to Apache Airflow and its architecture. Consider it a must-read if you’re a would-be data engineer, aspiring MLOps manager, or just interested in the modern data pipeline.
For as long as we’ve been able to harness its power, big data has been critical to business success – so much so, in fact, that big data has been famously compared to the oil boom. And with an expected market size of over $655 billion by 2029 (up from around $241 billion in 2021), the big data analytics market has boomed in turn.
That translates to quite a healthy career outlook for those who integrate and manage data. According to the U.S. Bureau of Labor Statistics, data science and computer research science careers are both growing “Much faster than average,” and the average salary for data and AI professionals was $146,000 in 2021.
Interested in carving out a path in this lucrative space? It all starts with knowing how to build and maintain a data pipeline. In this guide, we’ll show you the basics of using Apache Airflow, a workflow automation platform, to orchestrate powerful and secure data pipelines.
What is a Data Pipeline?
From customer lists in a CRM to the information mined from apps and analytics tools, businesses generate a ton of data. But if they want to make any sense of that data, the business must first be able to:
🔀 Extract data from multiple sources so it can be explored holistically
🧹Clean and transform the data to a standardized format that’s useful across data sets
💪 Load the data to the destination warehouse or a business intelligence tool for further analysis
The three high-level actions above guide the creation of the data pipeline, a series of steps governing the processing and transfer of data from Point A to Point B.
Data pipelines always kick off with batch or real-time data ingestion (batch processing is more common, and it’s generally recommended whenever having near-immediate data isn’t critical). From there, the pipeline can adopt a number of different architecture frameworks depending on where the data needs to go and how it needs to be transformed. The simplest possible data pipeline would look like this:
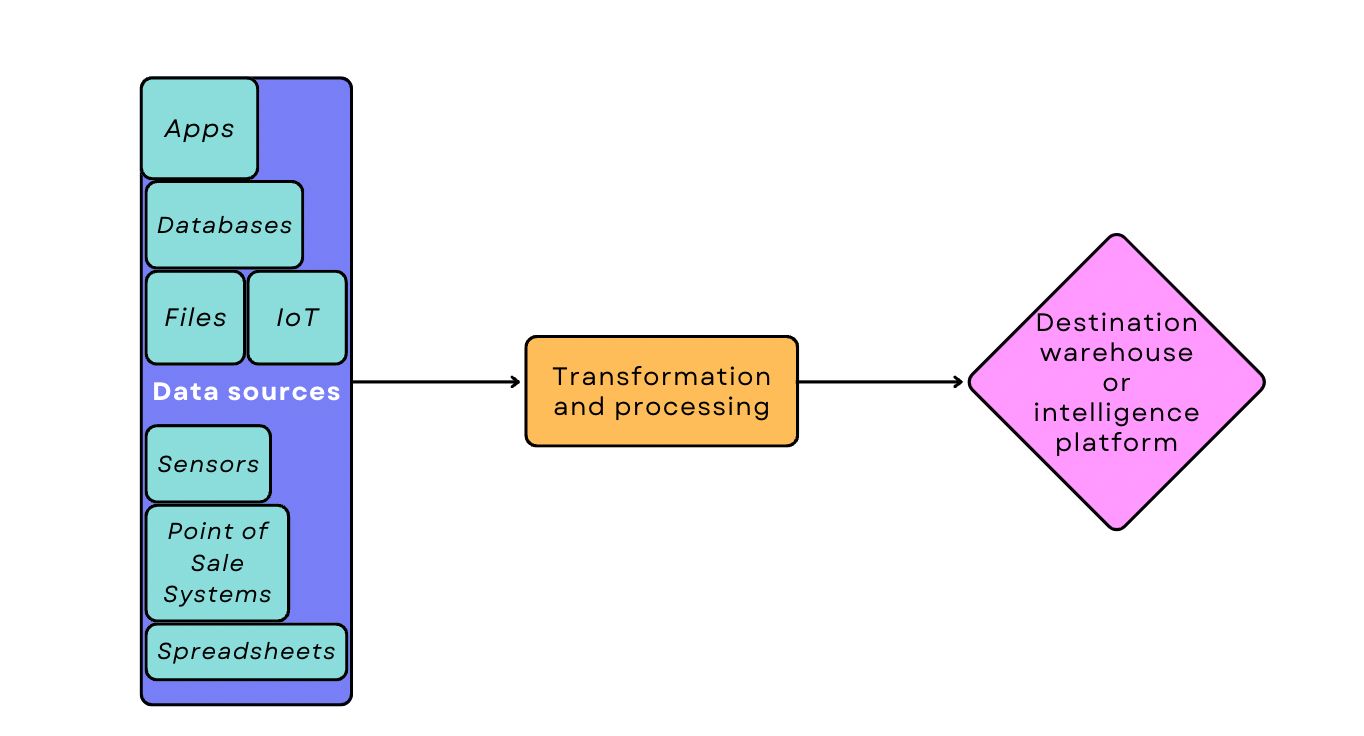
Most pipelines look a bit more complicated than that, though.
It’s common to perform a number of operations during the transformation and processing stage: cleaning and validating the data, deduplicating the data, combining data sets, changing data to a different format, or running basic calculations to create new data. Sometimes data must be pushed to other apps for transformation, then returned to the pipeline for further processing. Each additional step leads to more complex architecture.
What is Apache Airflow?
Apache Airflow is an open source platform that lets you create, schedule, and track workflows automatically.
The ideal data pipeline is fully automated, free from manual processes that introduce human error. Airflow is how you achieve that automation: it integrates with your processing tools and has them perform their work in a particular order, effectively powering up and running your pipeline.
For example, you might:
- Write a task that pulls data from the source to a staging location
- Write a Python task to clean the data
- Write a transfer task to load the data to a database
- Write a SQL task to run transform queries in the database
You could then use Airflow to perform these tasks in succession, at scheduled times or when certain conditions are met. The platform is like a symphony conductor, organizing the musicians and telling them when and how to participate. It doesn’t produce the music itself – but you wouldn’t have beautiful music without it.
Benefits of Apache Airflow for Data Engineers
So, why is Apache Airflow an important tool for a would-be data scientist or engineer to add to their toolkit?
Well, for one thing, it has already made a huge splash in the industry. There are currently more than 15,000 organizations using Airflow, spanning industries from retail to healthcare. The Walt Disney company, Nike, Walmart, JP Morgan Chase, and Zoom are just a few of the big names that have added Airflow to their stack. Amazon, Google, and Astronomer even offer managed Airflow services.
For another, Airflow makes developers more productive. You can monitor the workflows via notifications and alerts; see the status of tasks from the UI; and write Python code that generates pipelines dynamically. If Airflow's rich ecosystem of operators and sensors don’t meet your needs, you can write new ones using Python. And the platform’s full extensibility makes it customizable and infinitely scalable.
Since Airflow is open source, it also boasts a popular and enthusiastic developer community. The community makes the learning curve much less daunting; if you have questions or run into problems, there’s an army of people ready to help you (and if you take Uplimit’s Airflow Orchestration course, the army includes your instructors and coursemates!).
How Does Apache Airflow Work?
In Airflow, data pipelines are written in Python using a Direct Acyclic Graph (DAG). Organizing the workflow as a graph is a bit unconventional (as opposed to using a more standard architecture framework), but it helps you spot dependencies between tasks more easily.
In the DAG, tasks are represented as nodes, and the dependencies between them are direct edges between the nodes. The nodes use edges and connectors to communicate with other nodes and generate a dependency tree that efficiently manages the workflow. The visual DAG also provides a data lineage to assist with debugging and data governance.
Using the tasks and dependencies you’ve specified, you can then have a scheduler execute tasks at periodic intervals or when certain conditions are met. When you’re ready to deploy, both self-service/open source and managed service options are available.
Prerequisites for Using Apache Airflow
The prerequisites for using Apache Airflow aren’t extensive, but they do exist. To use the tool, you’ll need the following:
- Python prowess: Airflow runs on Python, so you’ll need to be able to write Python and work with documented libraries to use the platform.
- Docker: Running a DAG in Airflow requires installing Airflow in your local Python environment or installing Docker on your local machine.
- Familiarity with cloud environments: While it’s not strictly necessary for using the tool, it can also be helpful to have some experience with cloud computing environments like Amazon Web Services or Google Cloud.
Ideal Use Cases for Apache Airflow
Airflow’s architecture is flexible and scalable, making it a great fit for many use cases. More specifically, Airflow is an ideal choice when:
- You need to organize or monitor data flow
- You’re not relying on real-time/streaming data processing (Airflow works best with batch-based pipelines)
- You’re extracting data from multiple sources and/or transforming your data
The three high-level goals translate to the following use cases:
- Automatically generating reports
- Combining data from different platforms for a more complete view
- Performing data backups or other DevOps tasks
- Training machine learning models
Interested In Learning More?
We have more to teach you! Our Effective Data Orchestration with Apache Airflow course covers more than just the basics; we’ll also show you advanced features and let you loose on real-world projects. By week 2, you’ll be building a price prediction machine learning pipeline and loading it to the cloud. Not bad for your second week with Airflow, right?
Best of all, you’ll have an engaged, smart, inspiring community of peers and instructors who will be there for you every step of the way. Your instructors Henry Weller and Mike Shwe are experts in their field, and there’s an active Slack group baked into every course Uplimit offers.
Ready to carve another step forward in your career and learn an in-demand skill in just four weeks? Grab your spot today!